问题描述
有个每小时执行一次的定时mapreduce任务,在数据量差不多的情况下,执行耗时有很大浮动。快的在10分钟以内,慢的要20分钟以上。
问题分析
任务日志查看
yarn webui上做日志对比,发现执行耗时较长的任务都有一个特点,就是在task attempt列表中会有部分失败任务(如下图的任务,任务最终状态是success,但是有52个map task attempt失败了,这就意味着有task失败重试了)。通过下图对比可以发现,只要出现failed task attempt的任务,就会更耗时。那么优化的重点就是找到task failed的原因了。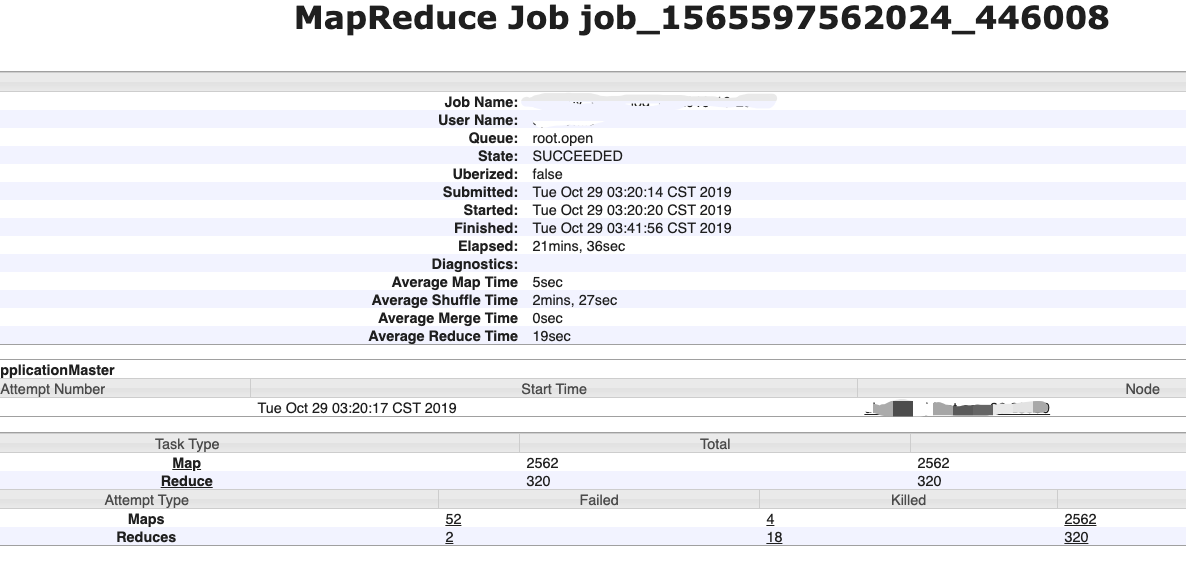
这里看到failed map task多是这样的:Container killed by the ApplicationMaster. Container killed on request. Exit code is 143 Container exited with a non-zero exit code 143 Too Many fetch failures.Failing the attempt
调整map reduce并行率
调整1:
看集群监控,看到部分时期yarn 可用vcores被耗尽,初步怀疑有map和reduce task并行执行,互相抢占资源。先修改了如下配置,保证默认所有map task执行完毕后再开始 reduce copy任务执行:
1 | #mapred-site.xml |
调整task container物理内存上限
调整1测试结果,发现依然有task attempt failed的情况。继续排查,这次看了yarn nodemanager的日志和application的执行日志。 有一个小发现:任务执行的task container物理内存上限是1024M, 从日志里的monitor监控看到,有时内存使用已经接近上限,所以考虑调整下task container的内存配置。
调整2:1
2
3#mapred-site.xml
mapreduce.map.memory.mb=2048; #默认为1024
mapreduce.reduce.memory.mb=2048; #默认为1024
调整reduce task获取map输出结果的并行线程数
调整mapreduce.job.reduce.slowstart.completedmaps=1之后执行的任务执行完成后,又仔细排查看里map task attemps和 reduce task attempts的时间,发现里一个奇怪的现象,通过对task任务的开始和结束时间排序发现,执行成功的map task并不是都在 reduce task之前结束。

再仔细观察,发现其实只有部分successful map task attempt是在reduce之后运行的。再与failed map task attempt一对比,可以发现,所有在reduce task之后才开始的 successful map task 都是failed map task attempt的下一次重试。从task attempt 编号可以看出来。

这样一拆解,我就大概明白为什么有成功的map task是在 reduce task开始后执行的了:
在任务开始执行的时候,由于设置了mapreduce.job.reduce.slowstart.completedmaps=1确实是2562个map task执行完毕后,才开始启动 reduce task, 而reduce task工作的第一步,就是去从各个map task输出的结果集中取本reduce task需要的那部分数据。但是由于某些原因(网络或者其他负载因素),部分map task的数据无法获取到,如果长时间获取不到需要的数据, reduce便认为这个map task执行失败了,告知application master去冲跑这个map task. 也就是说不管刚开始,这个map task是成功了,只要我reduce多次无法获取到这个map task的数据结果数据,我就告状说你这个map task失败了,让你重跑。 这样,failed map task attempt的报错显示也好理解了:
1.Failing the attempt Too Many fetch failures.
2.Container killed by the ApplicationMaster. Container killed on request. Exit code is 143 Container exited with a non-zero exit code 143 Too Many fetch failures.Failing the attempt
Too Many fetch failures.
应该都是reduce阶段长时间无法完成map结果数据获取,造成application master把原本完成的map task置为失败状态,并重跑对应map task. 至于exit code 143,多半和内存相关,也印证了上面调整的container内存的必要性。
在reduce优化相关的配置文件中看到了一个比较重要的:
mapreduce.reduce.shuffle.parallelcopies,默认值为5,这个参数是用于指定reduce task去提取map输出结果所启用线程的个数,本任务有2000多个map task,便尝试增大线程数到20,进行测试。
调整3:
1 | #mapred-site.xml |
另外,还看到有一些reduce task attempt是killed和failed状态.
报错为Reducer preempted to make room for pending map attempts的killed task,这些多半是因为yarn 资源不足,临时抢占reduce task,为失败重试的map task腾出执行空间。
failed的reduce task应该也是shuffle copy data from map阶段在特定时间多次重试后报错:
Error: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in fetcher#5 at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134) at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:376) at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1671) at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158) Caused by: java.io.IOException: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out. at org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl.checkReducerHealth(ShuffleSchedulerImpl.java:358) at org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl.copyFailed(ShuffleSchedulerImpl.java:280) at org.apache.hadoop.mapreduce.task.reduce.Fetcher.copyFromHost(Fetcher.java:308) at org.apache.hadoop.mapreduce.task.reduce.Fetcher.run(Fetcher.java:193)
结果
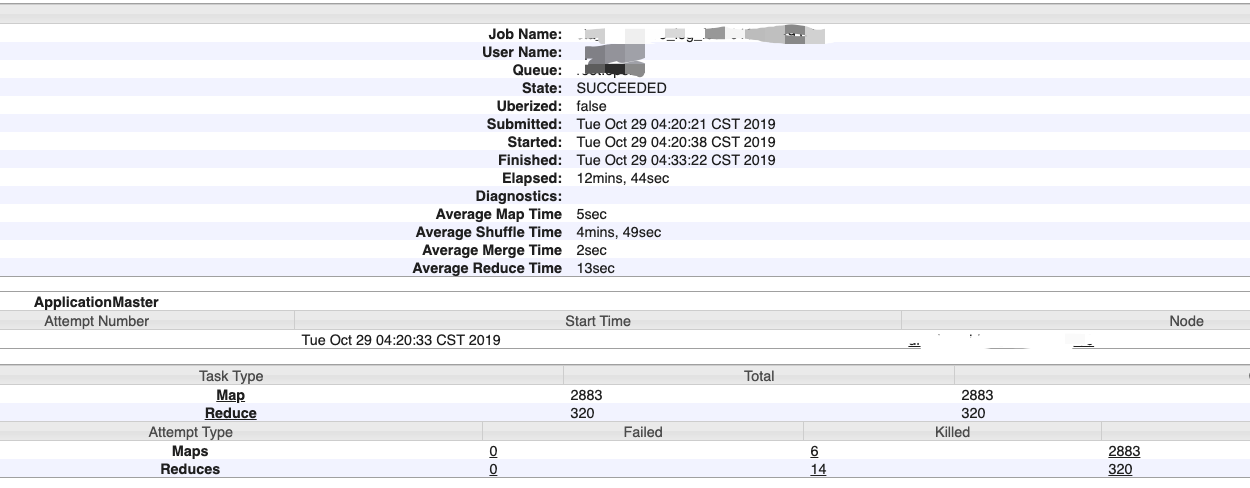
经过1,2,3的参数调整后,重启了yarn集群,重跑任务,观察了一天,发现任务不再出现失败重试造成延时的情况。并且,多数任务可以在五分钟内执行完成。
总结
在reduce阶段因为fetch map task数据失败造成map task重试或者reduce task失败的原因还有其他。比如:
- 集群网络带宽瓶颈;
- 集群磁盘io性能问题;
- 执行reduce task container的节点/etc/hosts配置的节点域名解析不全,漏掉部分节点配置;
- task container oom被kill;
- 甚至是hadoop节点宕机等情况。
具体情况,需要结合集群监控,任务日志和yarn日志等多方面分析去确定问题。
参考:
Hadoop-Mapreduce shuffle及优化:https://www.jianshu.com/p/d903dca59aac
mapred-site.xml基本配置参考:https://www.cnblogs.com/yjt1993/p/9476573.html
mapred-site.xml默认配置说明:https://hadoop.apache.org/docs/r2.7.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml